Spatial Semantics First Results
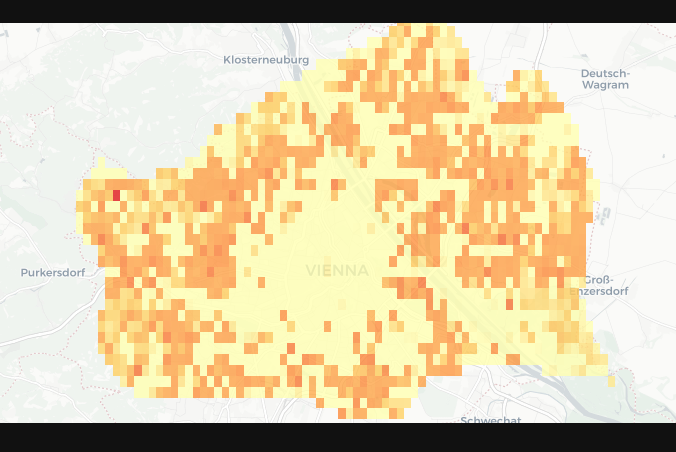
After a “longer” hiatus without any updates I finally have more than just some more code to show. As I described in my osm wiki parser post I can generate text for a given polygon from osm by querying the linked Wikipedia pages underlying OSM features. I created a raster for Vienna/Austria with a cell size of 0.005x0.005 degrees (I know degrees aren’t ideal ;) ). This results in 1853 cells. For each of these cells all the wikipedia text is downloaded and cleaned and than based on that an semantic (doc2vec) vector created. This already took a while because the overpass API server is limited to two slots every 2 minutes. But with these results I can now do the following enter a word or string (of arbitrary length for example a whole 5 page document) and return the cosine similarity cells in relation to the query string. And here are the results: (more red means a higher cosine similarity value sorry for now propper map key)
for the word “tree”:
for the word “vineyard”:
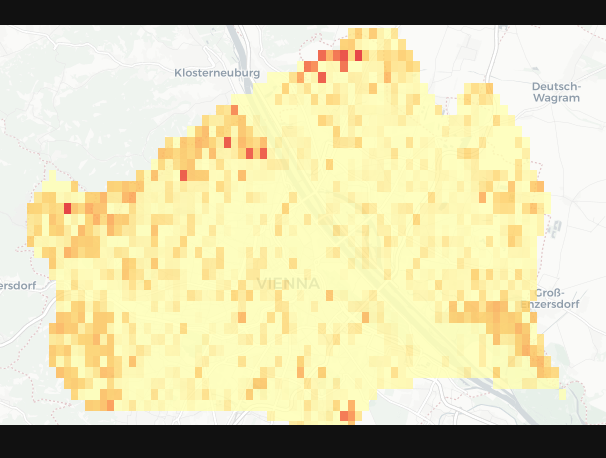
Broadly it looks like the system responds to the places where you would in Vienna expect more trees and vineyards to be. But when I try to use it further it also seems to create really high similarity values for cells that have comparatively lesser text in them. See the Vienna Lobau area in the vineyard example. My guess is that the cells at the moment are to large to work practically and thus drown a lot of signal.
example of to big cells:
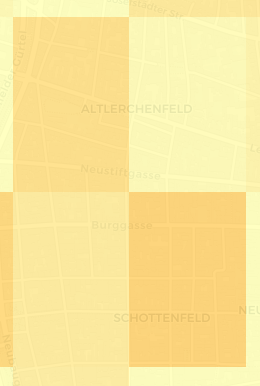
So the next step is to create smaller cells and repeat the experiment. I opted for a 50m cell size which will be about 200k cells for Vienna. With the current limitations of the overpass api I estimated this to take about 25 days of continuous computing this will take a while. I plan to be quicke this time around ;)